Why Faster Humanoid Deployment Exposes the Real Bottleneck in Physical AI

The Partnership Everyone's Talking About
Texas Instruments and NVIDIA just announced a partnership designed to accelerate the journey from simulation to safe deployment of humanoid robots. At first glance, this reads like another hardware story—bigger chips, faster processing, better sensors. The tech press will frame it as a race to build better robots.
But if you're actually building physical AI systems, this announcement exposes something more fundamental. It highlights a bottleneck that no amount of hardware acceleration can solve: the systems integration problem that kills most physical AI deployments before they reach production.
The real constraint isn't computational power. It's systems discipline.
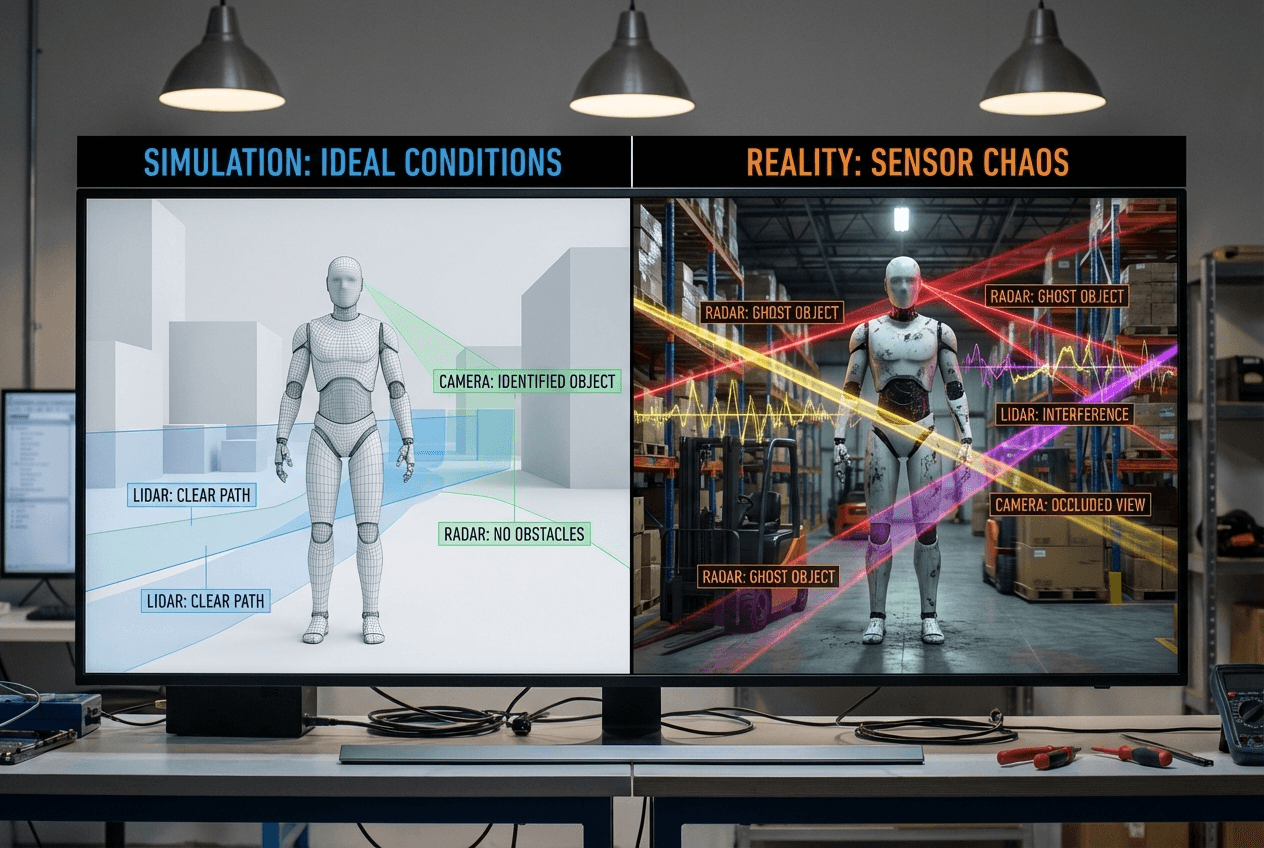
The Assumption That Breaks Everything
Most teams building physical AI operate under a dangerous assumption: better sensors plus more compute automatically equals safer deployment. The logic seems sound. If your robot can see better and think faster, it should perform better in the real world.
This assumption collapses the moment you leave the controlled environment of your lab.
In production, the bottleneck isn't perception accuracy. It's not whether your vision model can detect objects with 99% precision versus 95%. The real killer is synchronization failure between sensing, inference, and actuation under strict latency constraints.
Here's what actually happens: Your camera captures a frame. Your radar picks up movement. Your lidar builds a point cloud. Each sensor operates on its own clock, with its own latency profile, generating data at different rates. Your inference pipeline needs to reconcile these signals, make a decision, and command the actuators—all within a time budget measured in milliseconds.
When sensors disagree about what's happening in the world, your robot needs to make a decision. Fast. And that decision needs to be deterministically safe, not probabilistically optimistic.
Why Production Environments Break Your Models
Simulation environments are clean. Controlled. Predictable. Real environments are none of these things.
Cameras lie in low light. They struggle with glare, shadows, and rapid lighting changes. Your vision model that performed beautifully in simulation suddenly can't distinguish between a cardboard box and a person wearing brown clothing in a dimly lit warehouse.
Radar can see through glass and fog, but it lacks semantic context. It tells you something is moving at a certain distance and velocity, but it can't tell you whether that object is a person, a cart, or a swinging door.
Lidar gives you precise depth information, but it fails with reflective surfaces and struggles with rain or dust. It generates massive point clouds that need processing, adding latency to your pipeline.
Each sensor has failure modes. Each one lies under specific conditions. And in production, you encounter all these conditions simultaneously.
The constraint isn't adding another model to your stack. It's not fine-tuning your existing models for another 10,000 iterations. The constraint is enforcing guardrails on how conflicting signals are reconciled when you have 50 milliseconds to make a decision that could injure someone.
The Guardrail Architecture Nobody Builds
If you audit the architecture of most physical AI systems, you'll find sophisticated perception pipelines, elegant planning algorithms, and impressive control systems. What you won't find is explicit arbitration layers with deterministic behavior.
Here's what's missing:
Sensor arbitration under ambiguity. When your camera says the path is clear but your radar detects movement, which sensor wins? Most teams don't have an explicit answer. They let their fusion algorithm figure it out probabilistically. This works until it doesn't, and when it fails, the failure mode is unpredictable.
You need explicit rules: In condition X, sensor Y takes priority. When confidence drops below threshold Z, fall back to behavior W. These rules need to be deterministic, testable, and auditable.
Safe fallback states. What does your robot do when it can't make sense of its sensor inputs? Most systems try to keep operating, making their best guess with degraded data. This is exactly backward.
The correct behavior is to transition to a safe state. Stop moving. Signal for help. Don't attempt to navigate through ambiguity. Production-ready physical AI systems have explicitly defined safe states and clear triggers for transitioning into them.
End-to-end latency budgets. Your perception pipeline might run at 30Hz. Your planning algorithm might update at 10Hz. Your control loop might operate at 100Hz. How do these integrate? What happens when your perception pipeline takes longer than expected? Do you skip a frame? Do you use stale data? Do you halt?
Most teams don't have explicit latency budgets for each component and clear policies for what happens when those budgets are exceeded. They tune for average-case performance and hope the worst case doesn't happen too often.
Without these guardrails, faster deployment just means faster failure. You'll discover your edge cases in production instead of in testing. And in physical AI, production failures can mean damaged equipment, injured people, or destroyed trust.
The Systems Discipline Gap
The robotics community has spent decades building sophisticated algorithms for perception, planning, and control. We have incredible tools for simulation, training, and validation. We can train models on millions of examples and achieve impressive benchmark performance.
What we don't have is a mature engineering discipline around systems integration for physical AI.
Software engineers learned this lesson decades ago. You don't just write code that works in the happy path. You design for failure. You implement circuit breakers, timeouts, and fallbacks. You monitor latency budgets and error rates. You build systems that degrade gracefully under load.
Physical AI needs the same discipline, but with higher stakes. A crashed web server is annoying. A crashed robot is dangerous.
This isn't about being conservative or slow. It's about being systematic. It's about recognizing that the hard part isn't making your robot work in your lab—it's making it work safely in environments you can't fully predict or control.
What This Means for Builders
If you're building physical AI systems, here's the operational reality: marginal improvements to your perception models won't get you to production. Faster hardware helps, but it doesn't solve the fundamental problem.
Invest your time in designing deterministic guardrails between perception, planning, and control. Build explicit arbitration layers. Define safe fallback states. Enforce latency budgets end-to-end. Make your failure modes predictable and testable.
This work isn't glamorous. It doesn't generate impressive demos or benchmark results. But it's the difference between a robot that works in controlled conditions and one that ships to customers.
The TI-NVIDIA partnership will accelerate hardware development. That's valuable. But hardware acceleration only helps if your systems architecture can use it safely. The teams that win in physical AI won't be the ones with the best models or the fastest chips. They'll be the ones with the most disciplined approach to systems integration.
Because in the end, robots don't fail because they're not smart enough. They fail because their builders didn't think systematically about how all the pieces work together under real-world constraints.
The bottleneck is systems discipline. Everything else is optimization.


